
The digital transformation of businesses and the generation of huge quantities of data have created a demand for faster performance, more scalability and deeper real-time insights. Analyzing data is necessary to make tactical decisions, better serve customers, and increase efficiency. New technologies are being developed because the traditional ones aren’t capable of coping with their needs.
In-memory computing brings processing tasks in or near memory and supplies real-time insights that help business owners to make more informed decisions. Near-memory incorporates memory and logic chips in an advanced IC package with the idea of bringing memory and logic closer in the system.
Both in-memory and near-memory computing technologies are valid for different applications. Both boost data processing functions and drive new architecture, like neural networks. In both approaches, the processor handles processing functions, while both memory and storage store the data.
In-memory computing (IMC)
Data is growing faster than improvements in computing performance and in memory computing architecture provides a solution to the problem. Earlier forms of in-memory computing were based on conventional architectures and did not offer the maximum benefit. More recently, the introduction of new architectures and software has made a difference. They enable data traditionally stored on hard disks to be stored in the random access memory (RAM) of dedicated servers.
In-memory computing software allows for storing of data in a distributed manner. Operational datasets are stored in RAM across multiple computers. The whole dataset is divided into the memories of individual computers and this partitioning of data makes parallel distributed processing necessary.
In contrast to a centralized server managing and providing processing capabilities to connected systems, multiple computers in different locations share processing capabilities. Using RAM data storage and parallel distributed processing means in-memory computing is extremely fast and scalable.
There has been a rather piecemeal approach to using in-memory computing to date but now companies are starting to use in-memory computing platforms that
combine all in-memory technologies, such as in-memory data grids (IMDGs) and in-memory databases (IMDBs), to offer more control.
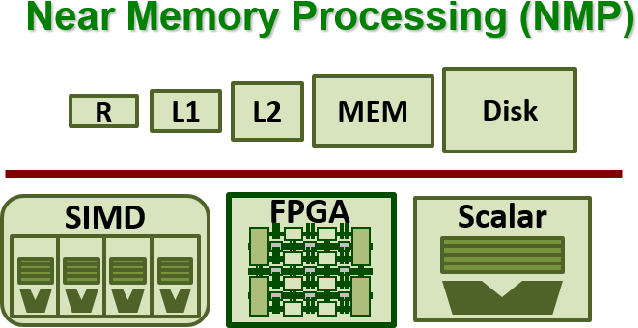
Near-memory computing (NMC)
The traditional approach is to move data up to caches from the storage and then process it. Near-memory computing (NMC) processes close to where data is stored instead.
Researchers began exploring the idea of near-memory computing some time ago and it was one of the earliest architectures designed to reduce latency and improve throughput. Reducing the distance from where data was stored to where it was processed held the promise of being able to run workloads faster and get results more quickly. However, there were some challenges to NMP in the 1990s and while the idea was sound, there was little momentum behind it.
The decade-old concept of near-memory computing (NMC) coupled compute units close to the data and sought to minimize expensive data movements. Advancements in new material and integration technologies have made this old concept more viable and there is renewed interest in it today.
Processors need large amounts of memory and the memory and the processor must be very close so packaging solutions are needed to enable this, whether they are 2.5D or fan out with a substrate approach. The industry is also working on 3D-ICs where the idea is to stack memory dies on logic chips, or logic dies on each other, connected with an active interposer.
Advantages of in-memory computing
Any market or industry requiring real-time insights finds them possible when using in-memory computing. By integrating in-memory computing, it is possible to accelerate machine learning on real-time and historical data for smarter insights and extremely fast response time. With an immediate understanding of the impact and consequences of customer actions, business operations, regulatory compliance and more, businesses can make appropriate responses quickly.
As it allows for collocation of logic, analytics and data, in-memory computing is about more than producing an analysis faster than before but about becoming predictive in that analysis.
The BFSI (banking, financial service and insurance) sector is expected to see the most adoption of in-memory computing. Fraud reduction, risk management and the rise in transactional and analytic requirements is driving demand.
Adoption of new technologies like in-memory computing and blockchain in the fintech sector can offer more security, super-fast, scalable performance, and simplify access to increasing numbers of data sources.
By using in-memory computing platforms, it becomes easier to manage, speed up and scale out existing applications and build new ones.
If one business can replan its supply chain in seconds and it takes another one hours, it has a problem from a competitive standpoint. If one business can dynamically change pricing of products in real-time and another can only change them once a day, the same applies. In-memory computing offers businesses this competitive advantage.
Advantages of near-memory computing
With new data-intensive applications, there is a need for new architectures. Researchers have been proving the potential of various NMC designs to increase application performance.
Near-memory computing addresses next-generation platforms that require higher bandwidth, more flexibility and increased functionality, while at the same time lowering power profiles and carbon footprint requirements.
Implementing computations in memory and not in the processor eliminates data movements between the memory and the processor, which reduces latency and power use.
The ability to integrate components in a single package means fewer circuit board layers and routing complexity is reduced because components are already integrated into the package. They enable a faster time to market because they integrate already proven technology and re-use common devices across product variants.
Conclusion
Traditionally the design of a computer separates compute and storage units. Processor logic units compute on data and memories and caches store data. The in and near-memory paradigm blurs this distinction and imposes a dual responsibility on memory substrates – that of storing and computing on data.
Modern processors have more than 90% of their aggregate silicon area devoted to memory. In-memory and near-memory processing converts these units into powerful ones for parallel computing and this can accelerate many applications. These architectures offer much higher bandwidth to access data and reduce data-movement costs.